The Intersection of Language and Mathematics: Thought and Structure
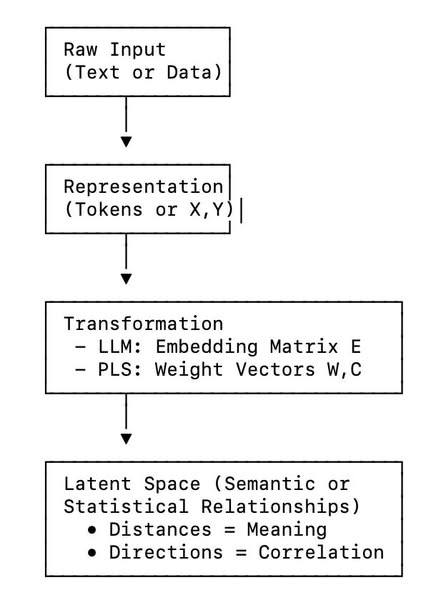
When we delve into the workings of Large Language Models (LLMs), a fundamental concept is tokenization. This process transforms the continuous flow of human language—rich with nuance and complexity—into discrete, countable units called tokens. These tokens can be words, subwords, or even fragments of meaning, depending on the specific model’s architecture. Once tokenized, each unit is then mapped to a vector in a high-dimensional space, a process known as embedding.
Within this embedding space, tokens that frequently appear in similar linguistic or semantic contexts are positioned closely together, while those with differing meanings are pushed apart. This effectively creates a geometric landscape of meaning, where the distance between vectors correlates with the similarity of usage, function, or semantic sense.
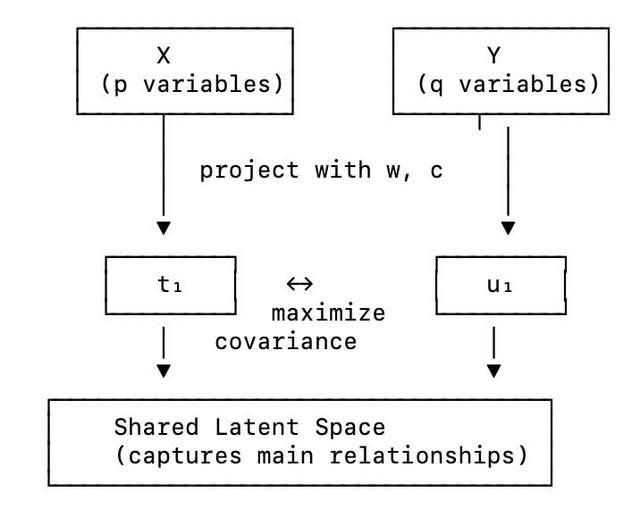
Interestingly, a similar principle underpins statistical techniques like Partial Least Squares (PLS) regression, albeit applied to numerical data rather than words. PLS operates on two matrices of observed data—typically X (predictors) and Y (responses)—and seeks to identify latent variables. These latent variables represent new axes or dimensions that optimally explain the covariance between the two datasets. Instead of working directly within the original variable space, which can be noisy, redundant, or highly correlated, PLS constructs a new latent space. This compressed, orthogonal coordinate system effectively captures the essence of the relationships between X and Y.
Both LLM embeddings and PLS share a central goal: To represent complex, entangled data in a new coordinate system where relationships become clearer and more efficiently computable.
Bridging High School Statistics to LLM Magic
To better appreciate the underlying magic of LLMs, let’s draw a closer parallel:
- In an LLM: Each token ti is represented by a vector {v}i. These vectors are derived from an embedding matrix E, which defines the model’s vocabulary size. Through extensive training, the LLM adjusts E such that similar meanings correspond to similar vector directions and magnitudes. Consequently, the “semantic relationships” between tokens emerge as geometric structures—clusters of related words, axes representing analogies, and smooth manifolds of interconnected concepts.
- In Partial Least Squares (PLS): Given a predictor matrix X and a response matrix Y, PLS identifies latent vectors t and u such that t = X w and u = Y c. The primary objective is to maximize the covariance: max Cov(t, u). This means PLS constructs latent components (new coordinates) that simultaneously compress the information in X and Y, while highlighting the strongest shared underlying structure between them.
In spirit, the connections are profound:
- The embedding matrix in an LLM functions similarly to the weighting vectors w and c in PLS—they both define projections into a new, meaning-rich space.
- The token embeddings themselves correspond to the latent scores t—coordinates within that transformed space.
- Just as PLS aligns X and Y to uncover shared meaning, the embedding model aligns textual forms with contextual meanings to establish semantic coherence. In a way, it achieves something Noam Chomsky might have dreamt of but perhaps never believed statistics could accomplish with sufficiently large datasets.
Both methods reflect a profound epistemological idea: that truth and structure are not always immediately visible in the raw data. Rather, they often emerge only after the data has been projected into an appropriate abstract space. Figures like George Boole, and later Chomsky, would have recognized this as the ongoing search for an underlying form of thought beneath surface manifestations—a latent structure that gives rise to observable expressions. PLS accomplishes this for numerical phenomena; LLM embeddings achieve it for language.
In both cases, dimensionality reduction serves as a fundamental act of understanding, revealing the essential axes along which variation holds meaning. In PLS, these axes might represent combinations of genes or economic indicators. In embeddings, they might encapsulate abstract yet quantifiable semantic dimensions such as “royalty,” “gender,” “time,” or “emotion.”
Stepping back, the connection can be expressed with a poetic elegance:
- PLS builds a latent world in which numbers remember their relationships.
- LLMs build a latent world in which words remember their meanings.
Ultimately, both are acts of translation—from the observable to the intelligible, from raw data to discernible patterns, and from noise to profound meaning.